配置 DynamoDB
权限配置
本地测试需要给当前用户的group配置DynamoDB的访问权限, Lamdba和EC2可以通过VPC来访问
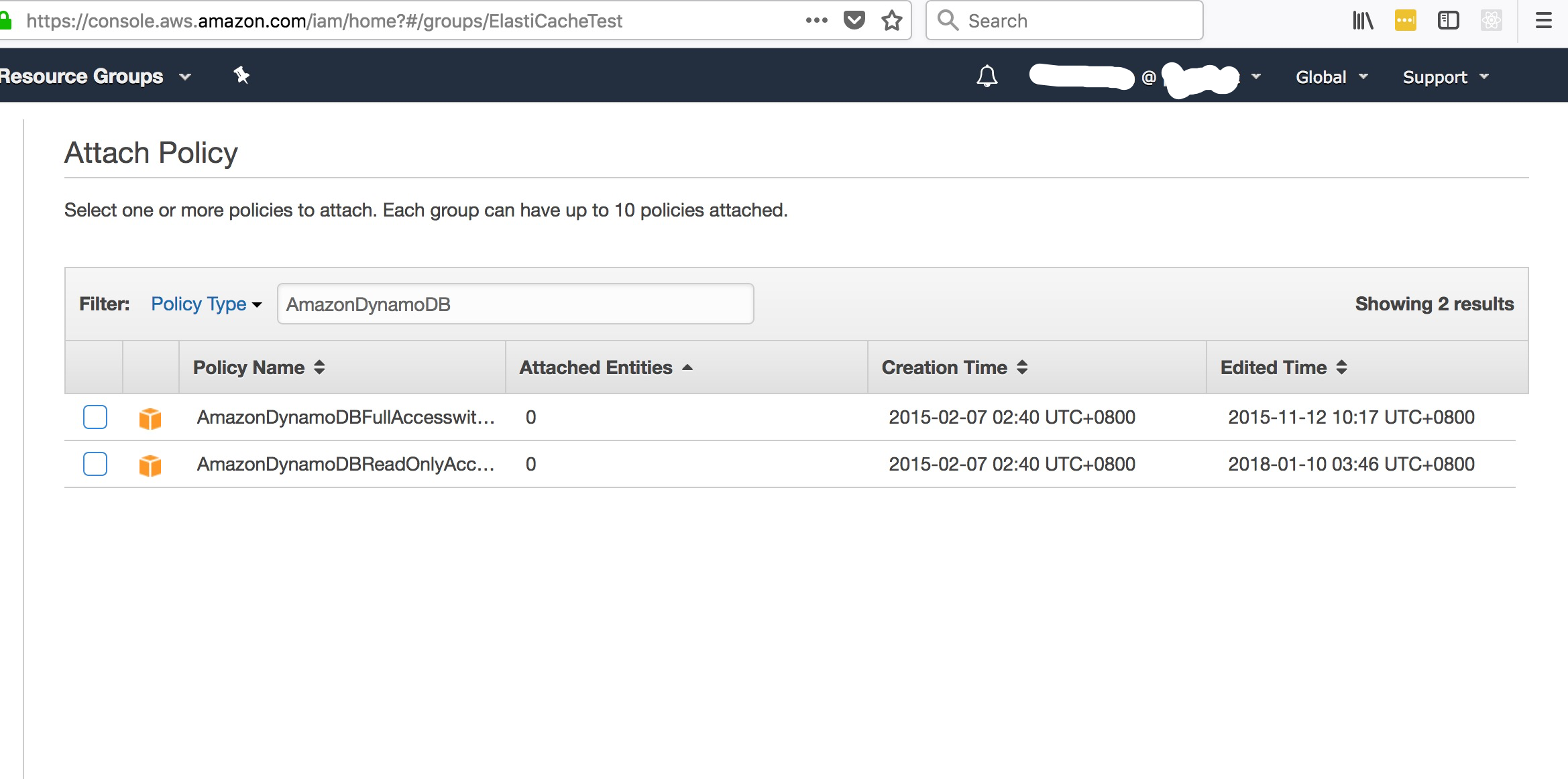
配置AWS Token
1 | AWS.config.update({ |
建模
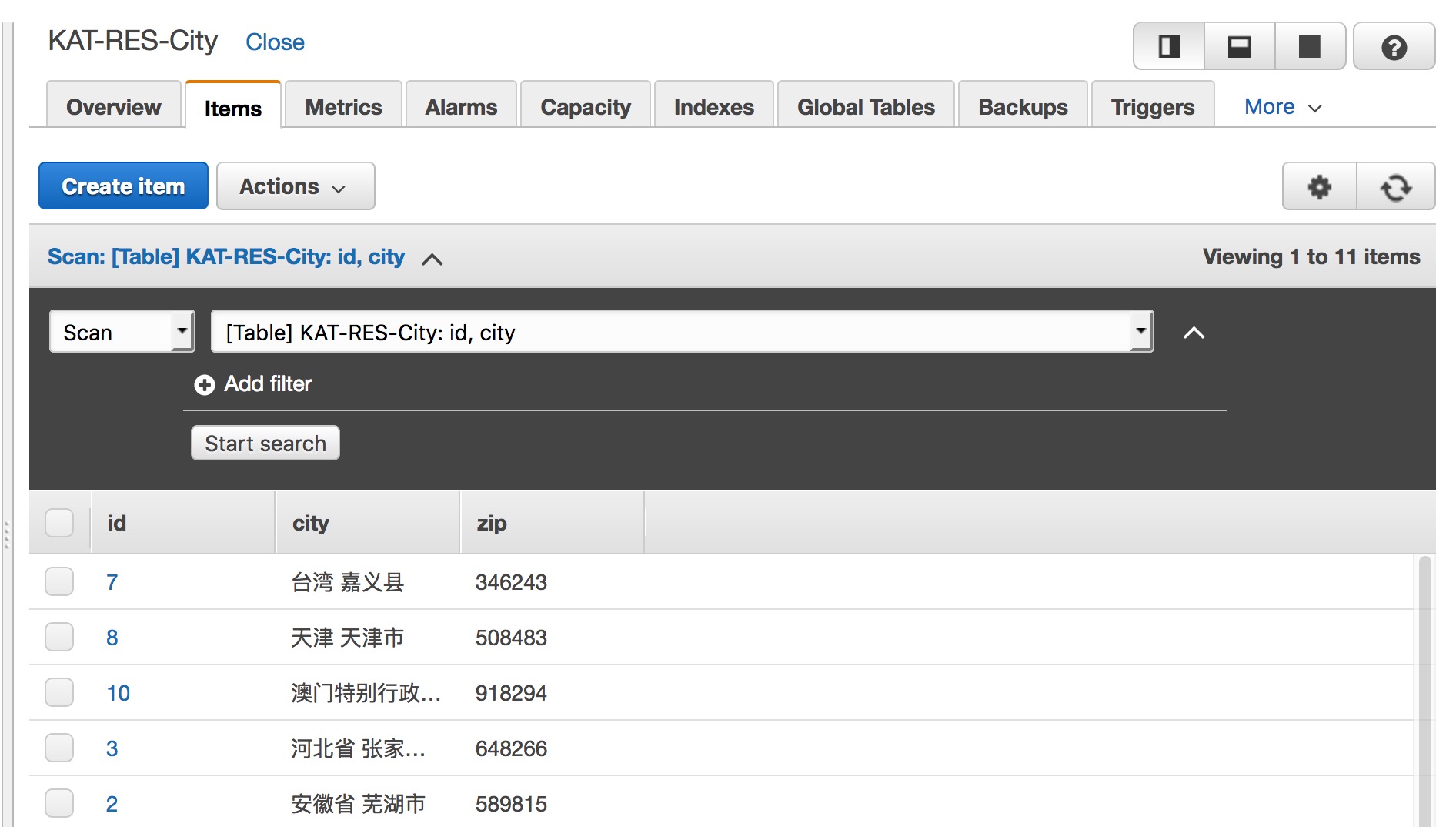
City表:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38{
name: 'City',
schema: {
fields: {
id: {
type: Number,
hashKey: true
},
city: {
type: String,
rangeKey: true
},
zip: {
type: String,
index: {
global: true,
rangeKey: 'city',
name: 'ZipNameIndex',
// project: ['creationDate'], // ProjectionType: INCLUDE
throughput: 5 // read and write are both 5
}
}
},
config: {
throughput: { // Sets the throughput of the DynamoDB table on creation
read: 5,
write: 5
},
useNativeBooleans: true, // Store Boolean values as Boolean (‘BOOL’) in DynamoDB
useDocumentTypes: true, //Store Objects and Arrays as Maps (‘M’) and Lists (‘L’) types in DynamoDB.
saveUnknown: true, // Specifies that attributes not defined in the schema will be saved and retrieved. This defaults to false.
// timestamps: { // Defines that schema must contain fields to control creation and last update timestamps. If it is set to true, this fields will be createdAt for creation date and updatedAt for last update
// createdAt: 'creationDate',
// updatedAt: 'lastUpdateDate'
// }
}
}
}
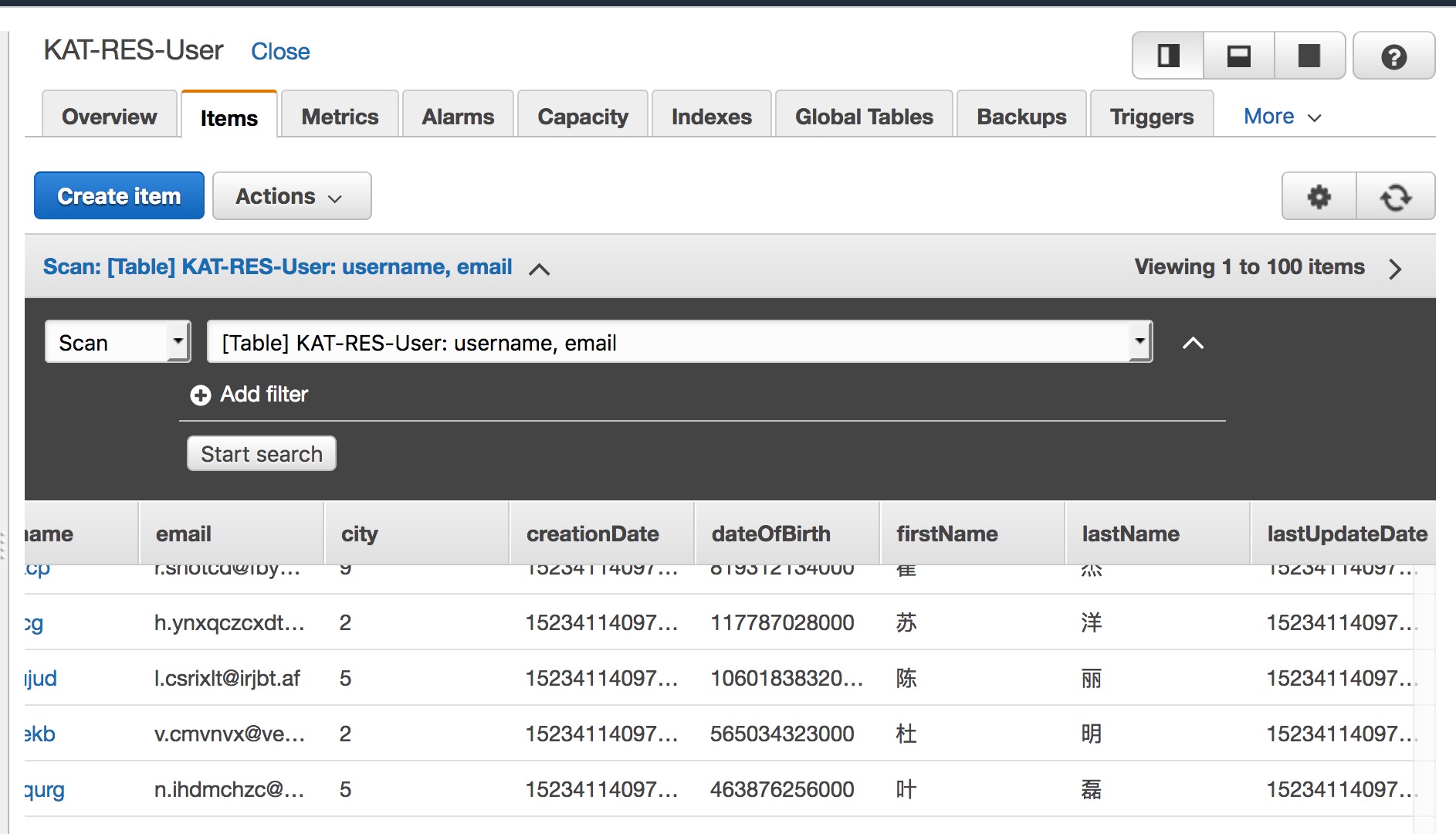
User表:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32{
name: 'User',
schema: {
fields: {
username: {
type: String,
hashKey: true
},
email: {
type: String,
rangeKey: true,
},
firstName: String,
lastName: String,
dateOfBirth: Date,
city: Number
},
config: {
throughput: { // Sets the throughput of the DynamoDB table on creation
read: 10,
write: 10
},
useNativeBooleans: true, // Store Boolean values as Boolean (‘BOOL’) in DynamoDB
useDocumentTypes: true, //Store Objects and Arrays as Maps (‘M’) and Lists (‘L’) types in DynamoDB.
saveUnknown: true, // Specifies that attributes not defined in the schema will be saved and retrieved. This defaults to false.
timestamps: { // Defines that schema must contain fields to control creation and last update timestamps. If it is set to true, this fields will be createdAt for creation date and updatedAt for last update
createdAt: 'creationDate',
updatedAt: 'lastUpdateDate'
}
}
}
}
创建表病导入数据
通过Test Case创建表, 并将mock-data.js产生的测试数据导入到数据库
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29it('City record should be batch added successfully', () => {
var allCities = JSON.parse(fs.readFileSync(normalPath + '/mock-data-cities.json', 'utf8')).data;
expect(allCities.length).to.be.equal(10);
var items = [];
allCities.forEach(p => {
items.push(new City(p));
});
return City.batchPut(items).then(data => {
expect(Object.keys(data.Responses)).to.have.lengthOf(0);
expect(Object.keys(data.UnprocessedItems)).to.have.lengthOf(0);
});
});
it('User record should be batch added successfully', () => {
var allUsers = JSON.parse(fs.readFileSync(normalPath + '/mock-data-users.json', 'utf8')).data;
expect(allUsers.length).to.be.equal(200);
var items = [];
allUsers.forEach(p => {
items.push(new User(p));
});
return User.batchPut(items).then(data => {
expect(Object.keys(data.Responses)).to.have.lengthOf(0);
expect(Object.keys(data.UnprocessedItems)).to.have.lengthOf(0);
});
});
在 DynamoDB Console 检查数据
Amazon EMR
Hadoop: 分布式文件系统 + MapReduceHive: 构建在Hadoop之上的数据仓库工具, 提供了简单的结构化查询语言, 可以将sql语句转换为MapReduce任务进行运行.
启动Hive集群
准备密钥对 (可选)
进入 EC2 Console, 配置密钥对
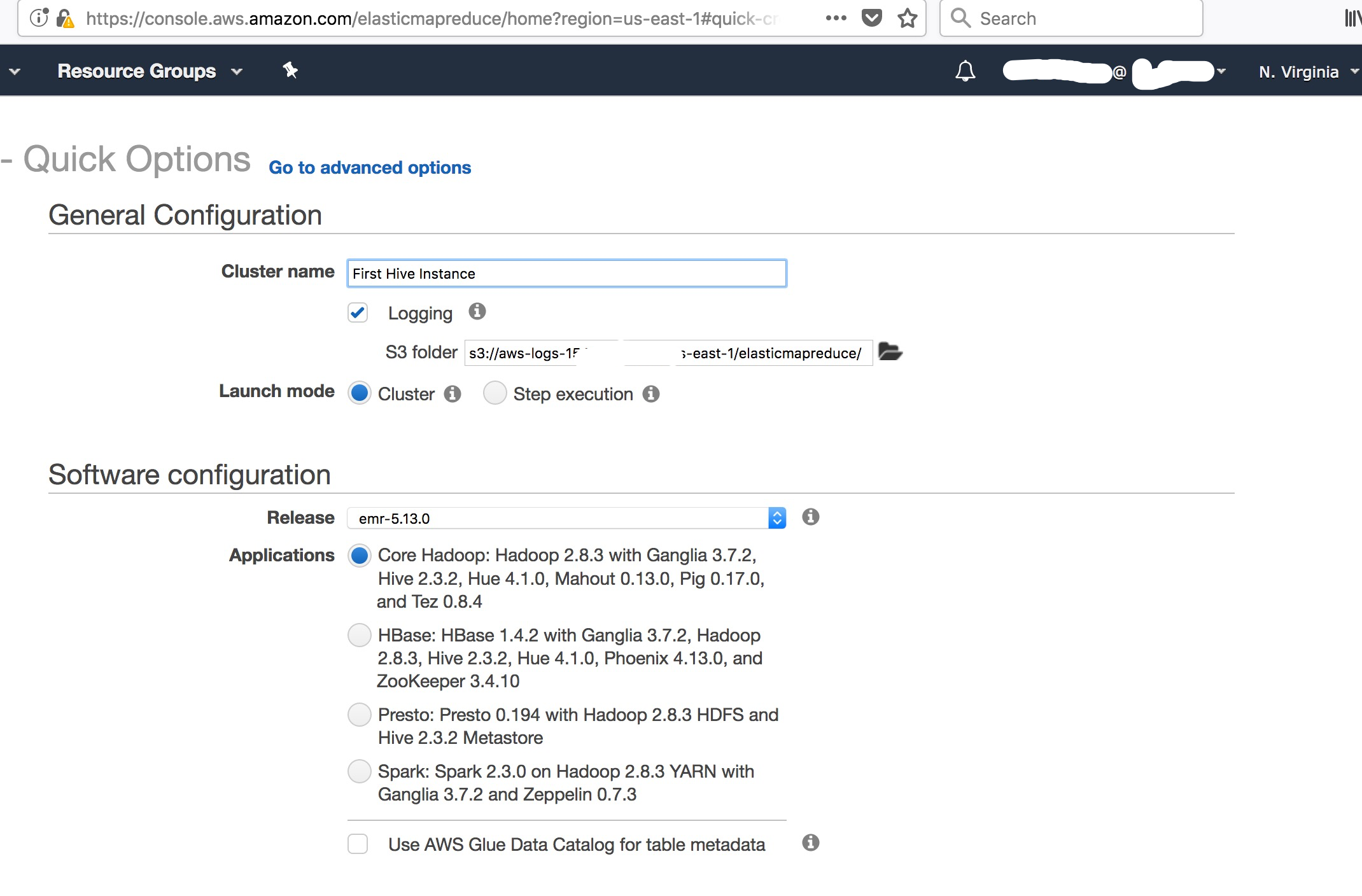
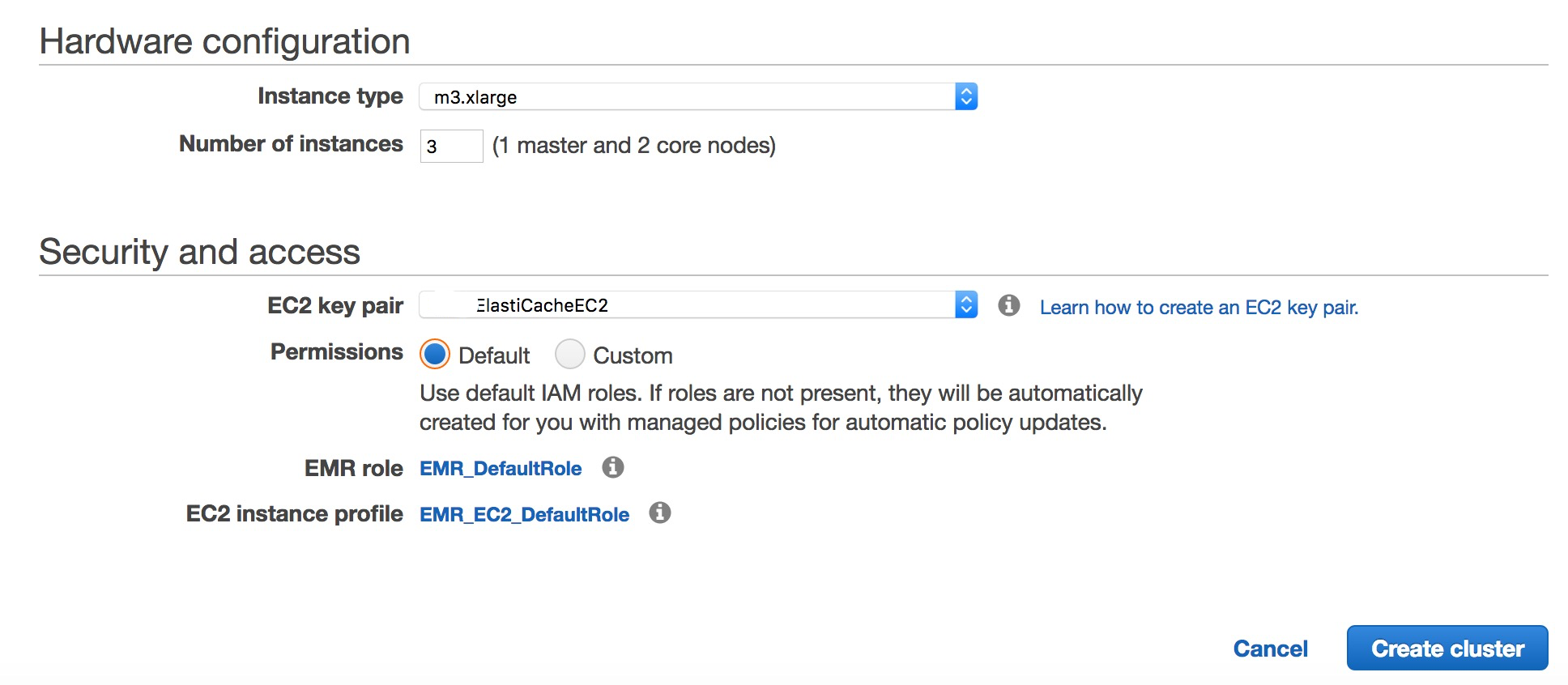
进入 Amazon EMR Console, 创建Hadoop集群

配置并启动Hadoop集群
注意配置密钥对, 后续测试相关:
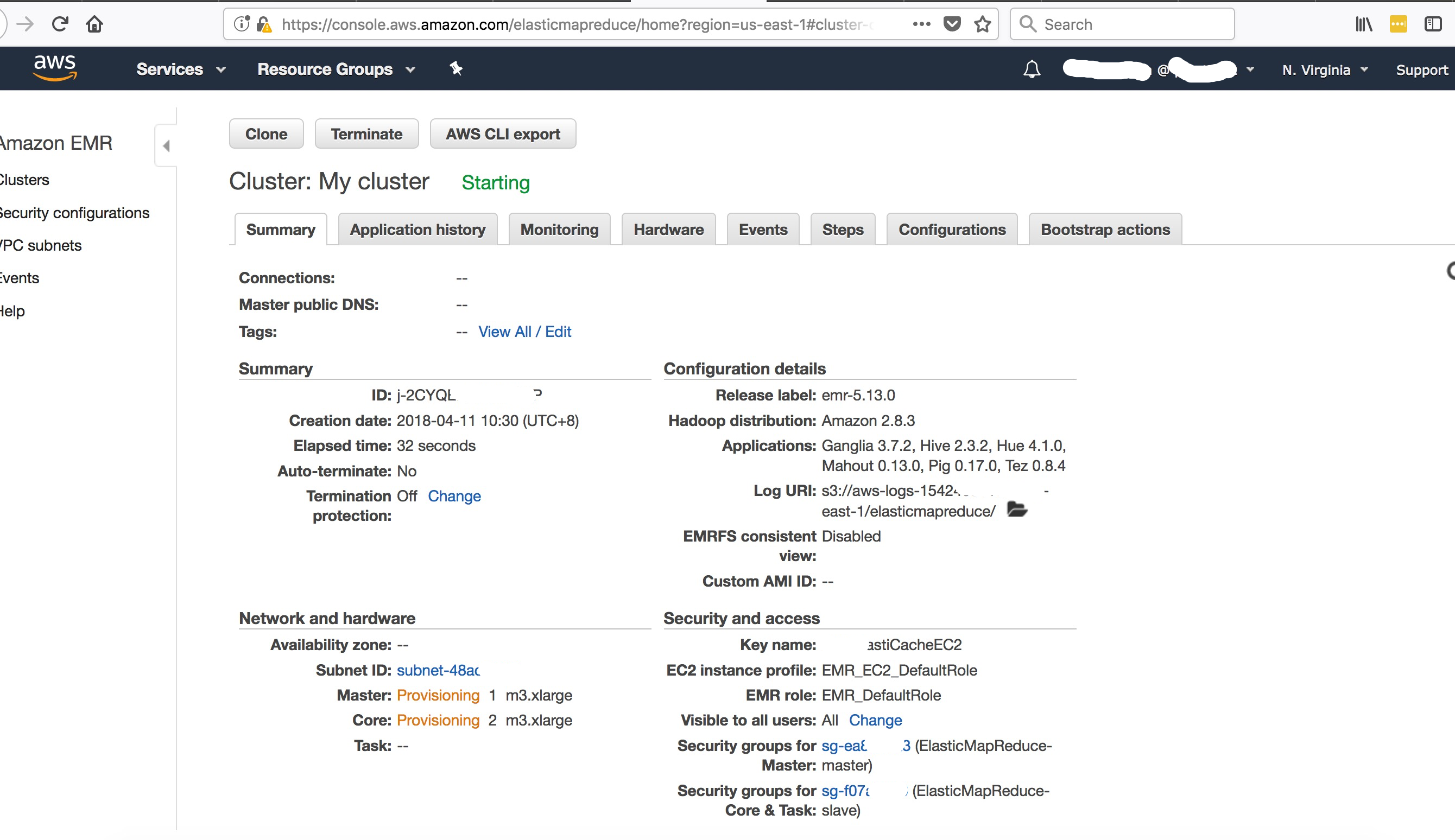
查看Hadoop集群详情
- 集群详情
- EC2 集群详情
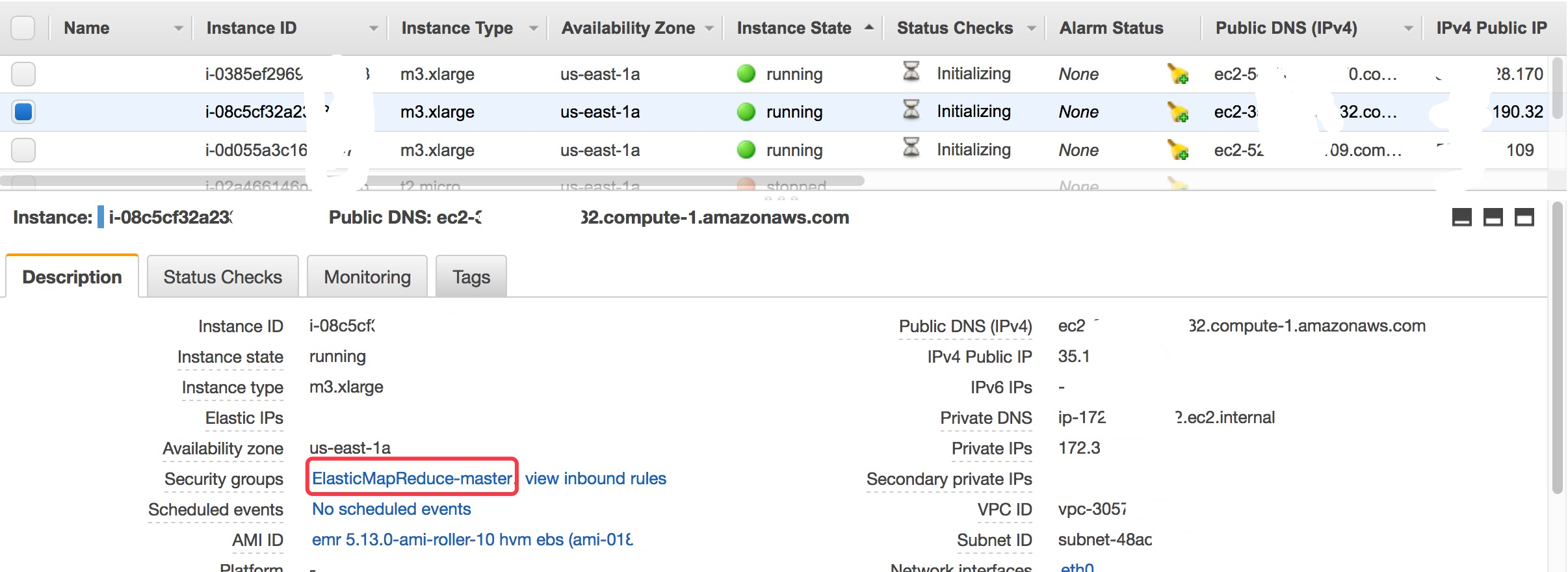
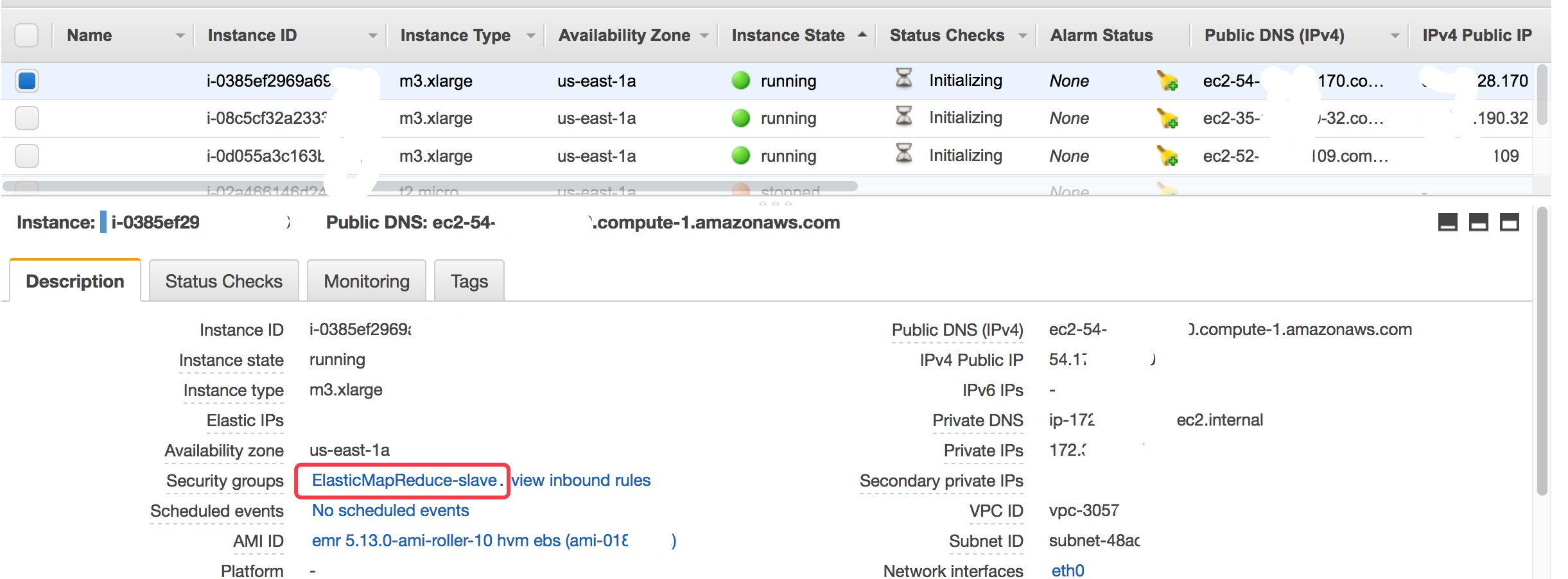
访问集成集群 (可选)
Hadoop集群已经启动, 我们可以通过SSH访问Hadoop
- 配置EC2的Security Group, 保证一些服务的端口可用, 比如ssh对应的20端口
通过SSH命令访问
1
ssh -i KAT-ElastiCacheEC2.pem hadoop@ec2-35-172-190-32.compute-1.amazonaws.com
- 测试
Hive命令:
DynamoDB集成Hive
使用 HiveQL 访问外部数据源(DynamoDB中存储的数据), 帮助我们处理并分析数据源
本地开发环境搭建
配置SSH 隧道
因为EC2没有配置Public IP, 所以我们通过SSH 隧道以方便在本地访问Hadoop集群:
1
ssh -o ServerAliveInterval=10 -i path-to-key-file -N -L 10000:localhost:10000 hadoop@master-public-dns-name
==>
1
ssh -o ServerAliveInterval=10 -i KAT-ElastiCacheEC2.pem -N -L 10000:localhost:10000 hadoop@ec2-35-172-190-32.compute-1.amazonaws.com
通过SSH 隧道将Hadoop集群master节点的10000端口映射到本地的10000端口上.
测试SSH 隧道
使用JDBC访问Hive.
- 可以通SQL Workbench/J来测试, 参考: 使用 Hive JDBC 驱动程序
- Java程序
Java程序通过JDBC连接Hive
下载Amazon Hive Jdbc Driver
下载: https://docs.aws.amazon.com/zh_cn/emr/latest/ReleaseGuide/HiveJDBCDriver.html
加载Amazon Hive Jdbc Driver
pom文件:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56<!--START local amazon hive jdbc driver dependencies. They are not in maven central/finra CM repo.-->
<dependency>
<groupId>com.amazon.hive</groupId>
<artifactId>hive_service</artifactId>
<version>1.0</version>
<scope>system</scope>
<systemPath>${project.basedir}/src/main/resources/libs/hive_service.jar</systemPath>
</dependency>
<dependency>
<groupId>com.amazon.hive</groupId>
<artifactId>HiveJDBC41</artifactId>
<version>1.0</version>
<scope>system</scope>
<systemPath>${project.basedir}/src/main/resources/libs/HiveJDBC41.jar</systemPath>
</dependency>
<dependency>
<groupId>com.amazon.hive</groupId>
<artifactId>libfb303</artifactId>
<version>1.0</version>
<scope>system</scope>
<systemPath>${project.basedir}/src/main/resources/libs/libfb303-0.9.0.jar</systemPath>
</dependency>
<dependency>
<groupId>com.amazon.hive</groupId>
<artifactId>libthrift</artifactId>
<version>1.0</version>
<scope>system</scope>
<systemPath>${project.basedir}/src/main/resources/libs/libthrift-0.9.0.jar</systemPath>
</dependency>
<dependency>
<groupId>com.amazon.hive</groupId>
<artifactId>ql</artifactId>
<version>1.0</version>
<scope>system</scope>
<systemPath>${project.basedir}/src/main/resources/libs/ql.jar</systemPath>
</dependency>
<dependency>
<groupId>com.amazon.hive</groupId>
<artifactId>TCLIServiceClient</artifactId>
<version>1.0</version>
<scope>system</scope>
<systemPath>${project.basedir}/src/main/resources/libs/TCLIServiceClient.jar</systemPath>
</dependency>
<!--END local amazon hive jdbc driver dependencies-->
<dependency>
<groupId>org.apache.httpcomponents</groupId>
<artifactId>httpclient</artifactId>
<version>4.1.3</version>
</dependency>
<dependency>
<groupId>org.apache.zookeeper</groupId>
<artifactId>zookeeper</artifactId>
<version>3.4.6</version>
<!--<type>pom</type>-->
</dependency>Load Driver Class
1
2
3
4
5
6
7
8
9private static String driverName = "com.amazon.hive.jdbc41.HS2Driver";
try {
Class.forName(driverName);
} catch (ClassNotFoundException e) {
// TODO Auto-generated catch block
e.printStackTrace();
System.exit(1);
}
连接Hive和测试
创建连接
1
2
3
4
5
6
7
8protected Connection con;
/** TODO: DOCUMENT ME! */
protected Statement stmt;
con = DriverManager.getConnection(JDBC_URL, "hadoop", "");
stmt = con.createStatement();执行SQL语句:
1
2
3public void test1DropTable() throws SQLException {
stmt.execute("DROP TABLE IF EXISTS MY_Table");
}
DynamoDB和Hive的表的映射
将 DynamoDB 表导出到 HDFS
通过Hive命令创建Hive外部表, 将DynamoDB的表映射Hive表中.
1
2
3
4CREATE EXTERNAL TABLE hiveTableName (col1 string, col2 bigint, col3 array<string>)
STORED BY 'org.apache.hadoop.hive.dynamodb.DynamoDBStorageHandler'
TBLPROPERTIES ("dynamodb.table.name" = "dynamodbtable1",
"dynamodb.column.mapping" = "col1:name,col2:year,col3:holidays");==>
1
2
3
4
5
6
7
8CREATE EXTERNAL TABLE HiveCity
(city_id BIGINT,
city_name STRING,
post_code STRING)
STORED BY 'org.apache.hadoop.hive.dynamodb.DynamoDBStorageHandler'
TBLPROPERTIES(
"dynamodb.table.name" = "KAT-RES-City", "dynamodb.column.mapping"="city_id:id,city_name:city,post_code:zip"
);映射表创建成功后, DynamoDB中的数据会及时同步到HDFS中.
查询Hive表
1
select * from HiveCity;
Hive表的做统计
AWS EMR的select count(*)默认是不工作的(参考 Amazon EMR的已知问题 ). 统计有以下两种实现方式:- 通过Hive命令
ANALYZE TABLE来做( 参考 ), 比如:ANALYZE TABLE HiveCity COMPUTE STATISTICS.
这个命令是执行一个MapReduce的Job来处理数据, 运行了ANALYZE命令后,count(*)才会得到正确的值.注意:
ANALYZE命令一次有效, 当DynamoDB的数据有增删的话, 再次运行count(*)是不会会得到正确的值(还是上次ANALYZE的结果). - 通过配置
set hive.compute.query.using.stats=false
Amazon EMR默认将其设置为true. 当关闭hive.compute.query.using.stats时, Hive的每条统计查询语句会转换成一条MapReduce的Job来执行(普通的查询语句不会转换).
这样的count(*)每次都会的到最新的结果.
- 通过Hive命令
多Hive表的俩和查询
由于DynamoDB不支持连接查询, 我们将DynamoDB的映射为Hive的多张表, 通过HiveQL的, 我们就可以做到DynamoDB的多表联合查询. 比如这条联合查询语句:1
select u.user_name, c.city_name from HiveUser u join HiveCity c on u.city_id = c.city_id
Hive将其转换成为MapReduce的Job来执行.
更多的查询语句: 查询 DynamoDB 表中的数据
Hive将数据复制到DynamoDB
Hive也可以将处理的后的数据在写入到Hive的DynamoDB的映射表, 相当于Hive将数据写入到DynamoDB中, 如下:
1
2INSERT OVERWRITE TABLE User_SNAPSHOT
select * from HiveUser where city_id = 1;
注意事项
如果JDBC执行HiveQL产生了MapReduce的Job(比如count(*), select … join …), JDBC连接必须配置用户名密码, 用户名为
hadoop, 密码为空.1
DriverManager.getConnection(JDBC_URL, "hadoop", "");
DynamoDB的吞吐量: Hive同步数据到DynamoDB会消耗DynamoDB的吞吐量. 我们需要根据实际的数据量大小来平衡同步速率和吞吐量 (参考 DynamoDB 配置的吞吐量 )
- 数据类型映射问题: DynamoDB和Hive两个的数据类型不是完全匹配的, 不是所有的字段都可以映射到Hive上的( 参考 )
- Hive有的查询语句会转换成为MapReduce的Job, 他不会马上返回结果, 需要等待Job执行完成. 这个过程在5s以上
- 在NodeJs里访问Hive的问题: 目前在NodeJS里头访问Hive是可以使用JDBC Driver做到的, 但是它需要JDK运行时, 所以在AWS Lambda - NodeJS上无法实现访问Hive.